TTS Paper Demo
Adaptive Condition Optimization for Text-to-Speech via Inference-Time Gradient Guidance
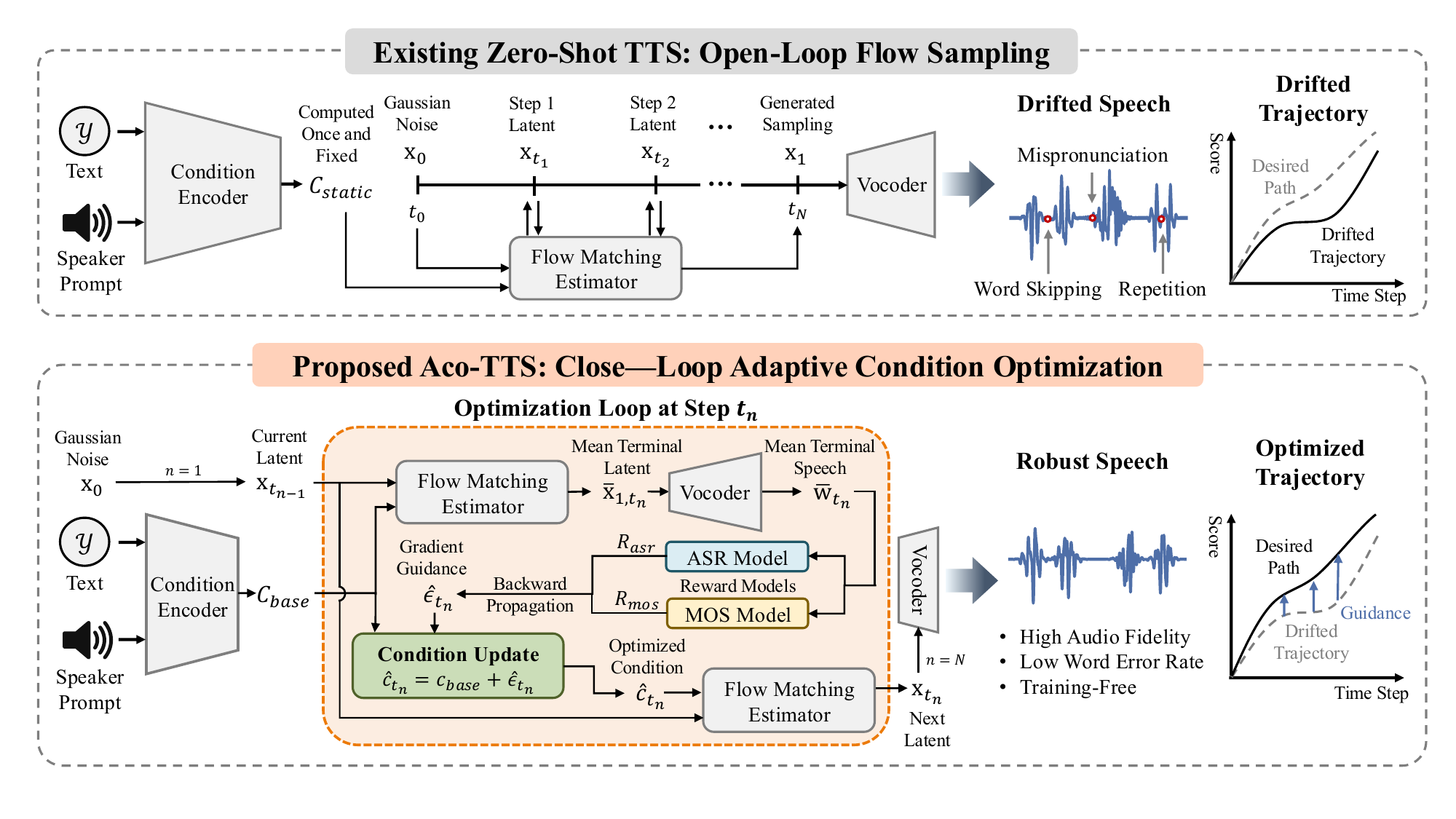
Main architecture overview of Aco-TTS and its adaptive condition optimization process.
Abstract
Existing zero-shot text-to-speech systems typically adopt a two-stage architecture combining a large language model with flow matching. However, flow matching follows an open-loop inference process without real-time correction during sampling, leading to speech distortion and unstable quality. A key limitation is that the condition is computed once before sampling and fixed throughout inference. Yet as the generation trajectory evolves, a static condition cannot adapt accordingly. To address this, we propose Adaptive Condition Optimization for Text-to-Speech (Aco-TTS), a gradient-guided framework for inference-time optimization that dynamically refines the condition during sampling using textual alignment and perceptual quality as guidance. This enables online correction and better constrains the flow trajectory. Aco-TTS is training-free and improves generation through gradient-based feedback at inference time. Experiments on SeedTTS, LibriSpeech, and AIShell-1 demonstrate significant reductions in word error rate and improvements in audio quality.
Audio Cases
Comparisons use the CosyVoice2 backbone baseline together with the two reward-guided variants from the paper: Aco-TTS-ASR and Aco-TTS-MOS. The English samples come from SeedTTS test-en, and the Chinese samples come from SeedTTS test-zh.